
北京时间3月9日中午开始了人机大战的第一场:Google的AlphaGo vs围棋九段李在石,历时约三个半小时,首战以AlphaGo告捷。有人欢喜有人愁。但无可否认的一点是科学技术越来越进步了。其中的功臣是AlphaGO背后的深度学习算法。深度学习是什么呢?深度学习为什么如此的火火火(重要的事情说三遍),它又为什么如此地牛呢?哪些方面又是它大展拳脚的地方?
我们再次跟随着上周百度少帅李磊博士精彩的分享(由太阁实验室举办的深度学习讲座),一探深度学习的奥秘。
1.什么是深度学习
深度学习其实是神经网络网络的品牌重塑。一提到神经网络,我们很容易联想到脑瓜里的千丝万缕。的确,神经网络(Neural Network)模型在发明之初是从人脑神经元这个概念得到灵感。首先我们看一个单一的神经元模型。
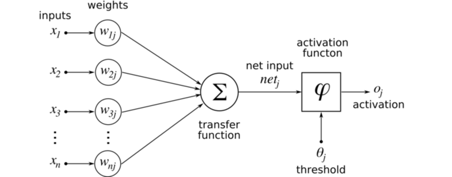
以图像为例子,每个数据或者输入就是一张图片,而里面的每个x可以是图片中的每个像素。对于每个像素我们都赋予一个权重,然后经过转换函数(Transfer Function, 这里是线性叠加)得到一个数值。简单来说,我们对所有像素做个线性加权叠加。得到的数值会经过激活函数得到新的数值。这个激活函数(Activation Function)往往是那几个符合某些特性的非线性函数。为什么需要非线性的转换呢?举个简单的例子,在同一个平面你和你的影子是重叠是分不开的,在立体的空间你们却能分开了。非线性的转换有类似的作用。常用的激活函数有relu, softmax, tanh。
在认识单个神经元后,我们再来看看以此为基础建立的多层神经网络和深度学习网络。
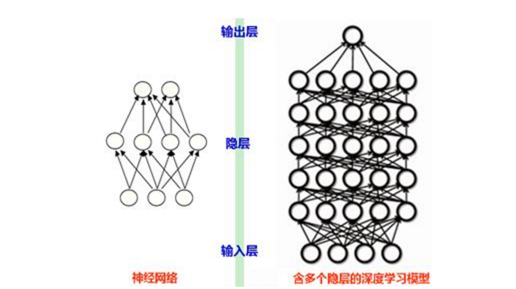
多层神经网络是,每一层神经网络经过转换函数和激活函数后的输出将会成为下一层神经网络的输入,经过从输入层到输出层一层层传播,最后输出结果。从上图可以看出,我们可以简单地认为深度学习是“层数进一步加深的”神经网络。譬如以前是两三层的神经网络,现在可以变成十层,甚至几十层。
这是深度学习,也是神经网络的基本结构。接着我们要提到另外一个基本概念:代价函数。在工作中有衡量表现好坏的指标,在机器学习中也有衡量模型好坏的指标,这就是代价函数。在测试数据上的代价函数值越低,就说明在测试数据上模型能力表现得越好。这并不针对深度学习,而是对于所有机器学习模型都适用。换句话说,代价函数可以作为模型学习训练过程(training)方向上的指导。常用的代价函数有cross entropy, hinge loss, least square。
在讲述神经网络常用的训练方法之前,我们提一个和代价函数联系的概念:监督学习。简单地说,妈妈在你小时候告诉什么是狗什么是猫。这里的“告诉”就是她的“监督”。你在她的“监督”之下分辨猫狗的过程就是一种“监督学习”。而深度学习常常也以监督学习的形式出现。代价函数代表着模型输出值与实际结果的误差,而误差作为反馈“一层层往后传播,从而修改模型的参数(譬如单个神经元模型里提到的权重)。这里“一层层往后传播”的训练方法就是经典的神经网络训练方法:反向传播算法(Back Propagation)。具体的实现有SGD,Adagrad,等等。
深度学习的三个重要方面(模型结构,代价函数,训练方法)已经介绍完了。那么我们接着说说为什么深度学习那么火。
2.为什么深度学习那么火
从1958年单层神经网络被设计,到1975年反向传播算法被发明,直到1996年Yann Lecun(Facebook AI实验室主任)才成功训练出第一个深度神经网络CNN,直到2006年,深度学习的发展才算出现转机。
曾经一度被打入冷宫,现在却又成为时代的新宠。是什么原因导致深度学习的发展曾一度停滞,又是什么原因使得现在的它变得如此之火?
其实,在最开始训练深度网络的时候,结果并不理想:层数的增加并没有提高准确率,反而提升错误率了。其中有个重要的原因在Sepp Hochreiter的博士论文中提到:梯度的消失。在反向传播分层训练(Back Propagation)的过程中本应用于修正模型参数的误差随着层数的增加指数递减,导致了模型训练的效率低下。
后来大家想出各种方法,缓解这方面的问题,使得“层数变得越深,效果变得越好”成为了可能。但是,为什么深度学习现在才火起来而不是以前呢?有两个原因:数据量的激增和计算机能力/成本。
 第一,机器学习里有一句非常经典的话,最后模型的成功不是取决于你的模型多好,而是你有多大的数据量。一般来说,越大的数据量,学出的模型也越好。而深度学习随着层数的增加,模型变得更复杂,从海量数据学习的能力也变得越强,也就越能利用大的数据量。
第一,机器学习里有一句非常经典的话,最后模型的成功不是取决于你的模型多好,而是你有多大的数据量。一般来说,越大的数据量,学出的模型也越好。而深度学习随着层数的增加,模型变得更复杂,从海量数据学习的能力也变得越强,也就越能利用大的数据量。
第二,虽然神经网络经过层数的增加变成表达能力更强的深度学习,但是随着层数的增加,模型的复杂度,训练时间也会增加,少则几个小时,多则需要多台机器运行几天。这也就是为什么在1996年,哪怕Yann Lecun第一次成功地训练出深度学习网络CNN,深度学习却没有在那时火起来的原因。然而现在,单机的计算能力越来越强,而价格也越来越便宜。科学家和企业,通过廉价的计算机集群比起以前更快地训练出深度学习模型,甚至通过GPU(硬件中的图像处理单元)来一定程度避免了“梯度的消失”的问题。
但最直接的原因就是它跑出远远超过其他算法好的结果。譬如在2012年的Large Scale Visual Recognition Challenge中,当大部分其他研究小组还都用传统计算图形算法时,多伦多大学的Hinton发出了深度学习这个大招。差距是这样的:第一名Deepnet的错误率是0.16422, 第二名日本东京大学的错误率是0.2617,第三名牛津大学的错误率是0.2679。
再加上媒体铺天盖地的宣传,深度学习的火爆可谓集齐天时、地利、人和。
3.深度学习有什么用
那么深度学习有什么用呢?它可以和你下棋,你很有可能赢不了它。

百度的自动车装载深度学习系统,它可以带你游山玩水,万里无忧。它能做出比人类还高的语音识别率。它甚至能“看图说话”或者“看图问答”。
 深度学习效果真的很卓越,但是它并不是万金油。虽然很久以前它已经存在,但现在才是深度学习在各个领域大展拳脚的时候。其中自然语言处理和图像视觉是它最得心应手的领域之一。那么接着我们跟随着李磊博士的脚步,简单了解一下百度在深度学习语义和视觉理解方面做出的努力和贡献。
深度学习效果真的很卓越,但是它并不是万金油。虽然很久以前它已经存在,但现在才是深度学习在各个领域大展拳脚的时候。其中自然语言处理和图像视觉是它最得心应手的领域之一。那么接着我们跟随着李磊博士的脚步,简单了解一下百度在深度学习语义和视觉理解方面做出的努力和贡献。
4.卷积网络与回归式网络
在进一步介绍百度的深度学习应用之前,我们需要了解两个重要的神经网络类型:CNN和RNN。如果您对此有所了解,可以直接跳过。
CNN,全称为Convolutional Neural Network。不过它的发明者Facebook AI实验室主任Yann Lecun更习惯把它称为Convolutional Network(卷积网络),而不再和人脑扯上联系。CNN可以由不同的部分组成,这里只讲最主要的部分:Convolutional Layer(卷积层)。 从直观上出发,图像上可以收集的常用特征有:点,角,边。它们在二维平面的分布以及它们的本身可以一定程度表征物体。如果你有计算视觉的背景的话,你会更清楚我说的这些特征具体可以是HoG,SIFT,等等。获取这些特征的方法都是类似的——通过一个filter对图片做卷积运算获得这些特征。下图很好地展示这个过程:粉红色小正方形代表的是filter,右边的每个“乒乓球”就是对整张图扫过一遍后得到的一个个值。以前的方法是人工设计这些filters,而卷积网络的关键是把filter当成是不确定的,通过数据和神经网络学习出使代价函数代价最低的filter。从生物视觉方面理解,我们看东西的时候常有视觉聚焦的时候,被聚焦的部分会有更清晰的特征, filter也是根据同样的直观。
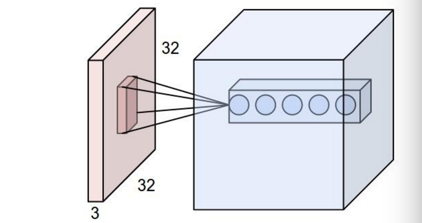
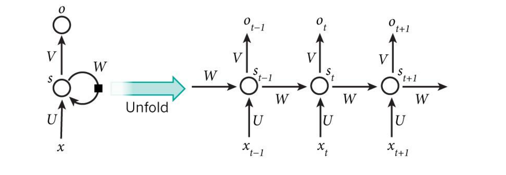
RNN,全称是回归式神经网络,Recurrent Neural Network,在1980年被首次提出。以下的图很好表明它的特点,和一般向前传播的神经网络不一样,它会通过W(其实也是个矩阵)传回自己那一层。这里的s代表它的“记忆状态”。从左边的图展开到右边的图我们可以看到,它把它的“记忆状态”不断往前传播。后一个“记忆状态”的改变依靠于前一个“记忆状态”和输入x。所以比起输入长度是固定的一般神经网络,RNN可以处理任意长度的输入。所以RNN本身很适合处理语言,声音之类长度不定的输入。最后补充一个和RNN经常一起提起的概念:Word Embedding。简单地说,它就是把词或者词语从词典映射到实数向量。神经网络本身可以实现这种映射,譬如图下W,U的部分就可以是代表Word Embedding的转换。
5.应用一:语义解析
自然语言处理可以分为两个大块:语言理解和语言生成。而语义解析都可以为这两大块所用。
我们先看个具体的例子。在百度地图搜索里,当我们输入“武汉理工大学附近的拉面馆”这样的搜索查询时,语义解析就会一显神通。语义解析可以认为本质上是个分类问题。譬如说,机器需要知道“武汉理工大学”是属于center这个类,而“拉面馆”是keywords这个类。然而它又不是个简单的分类问题——词语之间或者字母自己的依赖关系可以为准确的分类提供更可靠的信息。
那么我们看一下百度处理这个问题简化版的深度学习模型。
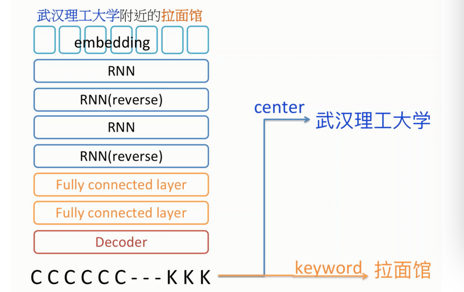
像之前所说那样RNN很适合处理语言这种输入——长度不定,然后每个字符或者每个词对于前面的词有依赖关系。首先embedding是把字符映射到数值向量的空间。数值化是便于比较和计算。然后这里有共四层的RNN与RNN(reverse)交替出现。每一对RNN与RNN(reverse)分别充当encoder与decoder,然后共同组成Autoencoder。Autoencoder字面上意思是自编码,大家可以认为这就像压缩和解压缩的过程。当学出这个Autoencoder就可以认为学出这些数据比较好的表示,可以进一步用作其他的任务。剩下其他的部分和一般的神经网络无异。另外补充一句,这里的fully connected layer意思是,现在一层的每个神经元都会连接到下一层所有的神经元。
上面的例子简单地介绍了用RNN处理语义解析的问题。语义解析不是只有深度学习才能做到,其中概率图模就是一种常用解决方案。但由于深度学习给出了更好的结果,所以受到更多的关注和青睐。语义解析有很多应用,譬如实体识别(识别出地点,人名等等),语法分析(譬如找出主谓宾),机器问答(譬如在一篇文章里,识别中那些词对应的是Harry Potter)。
除了语言理解,百度还致力于语言生成,譬如在百度的Neural Casual Chatting Machine里,百度就通过深度学习模型实现人机对话。譬如以下的例子,人类问了一句“星球大战好看吗?”机器回了一句“不很好看”。
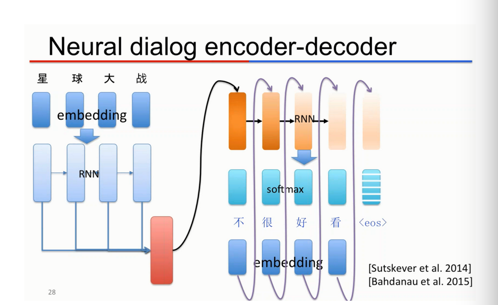
可以看出这个模型和语义解析的模型很相似,一样利用了RNN的特性。不过这个模型不再是个分类模型,而是个生成模型。经过第一个RNN输出的值不再用来分类,而是作为语言/回答生成的依据。仔细观察这个模型语言生成的流程,就会发现和之前RNN“记忆状态”传递的过程很像——每个字的生成都是由一层RNN(橙色部分)产生的,并且根据的是上一层的RNN的输出(“记忆状态”)和前一个生成的字(譬如“很”的前面是“不”)为依据。
6.应用二:图像字幕
根据语言可以产生语言,那么根据图像可以产生语言,也就是描述性字幕吗?答案是肯定的。
观察深度学习的语言生成模型,一个很自然的想法是把之前的语言生成模型的encoder部分把适合自然语言处理的RNN换成适合图像处理的CNN。
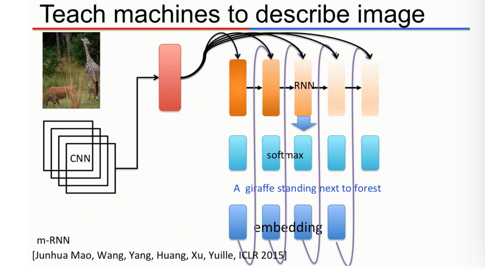
当然事情没有那么直接明了。百度深度学习研究院的博士实习生Junhua Mao在处理这个问题式用了个“夹心饼”模型m-RNN, 全称是Multimodal Recurrent Neural Network。我们可以简单地认为是CNN+MultiModal+RNN。在他的论文中,RNN整体结构基本不变,只有在Recurrent和CNN之间加上Multimodal的融合。简单地说,这个模型对CNN,Recurrent和Embedding得到的值做线性相加,然后把得到的值映射多态分布(Multimodal Distribution)空间。
既然可以根据图像产生字幕,那么根据视频产生字幕应该不会有大问题吧?最近百度被CVPR(图像视觉方面的顶级会议)2016收录的一篇文章“Video Paragraph Captioning using Hierarchical Recurrent Neural Networks”就是用深度学习的方法解决这个问题。这里比较关键的一个地方是如果采用之前“图像字幕”的方法会忽略一个视频里不同段之间的联系。所以百度利用Hierarchical RNN实现了Paragraph RNN,考虑这些联系,并对视频产生更有联系的段落描述。
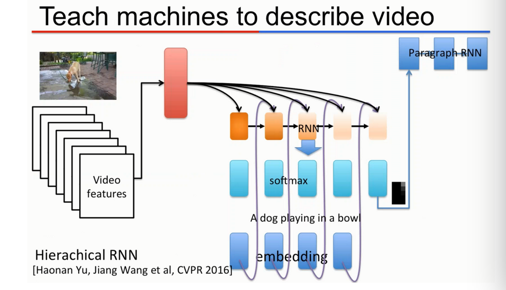
7.应用三:图像问答
既然可以对图像进行描述,那么可以根据描述进行图像问答吗?答案依然是肯定的。如果只是用传统的方法,就会出现下图的问题——当问蛋糕颜色的时候,机器可能把重点当成蛋糕上面的水果了。为了解决这个问题,百度在CNN的基础上建立Attention-based CNN,从问题中提取重点,譬如“cake”,然后从图中映射到值得注意的部分(Attention),譬如蛋糕的身体,从而降低回答的失误率。

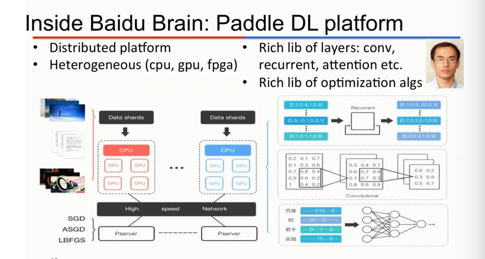
8.Paddle:百度的深度学习异构分布式系统
百度深度学习研究院的首席科学家吴恩达(Coursera创始人)曾经说过,“重要的不仅是机器学习算法本身,还有能实现它们的平台”。而支撑起之前提到的应用的功臣就是百度的深度学习异构分布式系统Paddle。Paddle每一部分的功能和层次都非常分明——底层把异构的计算资源(CPU,GPU,FPGA)封装起来起来,模型本身(CNN,RNN,Attention)也和具体的训练/优化方法(SGD, LBFGS)独立分开。
9.总结
从语义分析,到图像字幕,到图像问答,李磊博士给我们展示了百度在应用深度学习的过程中如何一步步改进模型,使它适用不同的情景。对于初战告捷的AlphaGo,它背后的两个主要深度学习网络(走棋网络和估值网络)也经历这样一步步进化的过程,感兴趣的朋友不妨了解一下https://bit.ly/1LRZyPx。
然而深度学习不是万金油。在它提供更通用和更有效的解决方案的同时,它在不同情景的使用依然需要大家经验的积累和对问题的思考。虽然依靠着现代强大的计算能力发光发热,但现在的它更像个黑箱子。背后的原理需要大家共同努力发现。
10.资料汇总
网上好的资料很多,笔者稍微总结一下。
想了解神经网络基本原理,包括数学模型,激活函数和代价函数的选择,反向传播算法的推导,可以观看Coursera里由Andrew NG(斯坦福吴恩达教授)教授的Machine Learning
想一个更统一的角度看CNN与RNN的话,可以了解斯坦福图形视觉大牛老师FeiFei Li的门徒Andrej Karpathy的博客:
The Unreasonable Effectiveness of Recurrent Neural Networks
对于深度学习的使用李磊博士推荐百度的平台和CMU的MXNET:
笔者本身尤其推荐Keras (python 深度学习库)。它吸收了Torch(lua语言的深度学习库)的模块化和最小化的思想,非并包括丰富的例子: keras/examples at master · fchollet/keras · GitHub。本文的例子很容易通过它来搭建,并有已经实现的例子
想了解CNN一层层学习的过程,并有可视化,请阅读The Keras Blog
RNN with word embedding: Recurrent Neural Networks with Word Embeddings
语言生成模型:
图像字幕(生成):https://arxiv.org/abs/1412.6632
视频字幕(生成):https://arxiv.org/abs/1510.07712










